Overview
EDITVAL is a standardized benchmark for evaluating text-guided image editing methods across diverse edit types, validated through a large-scale human study.
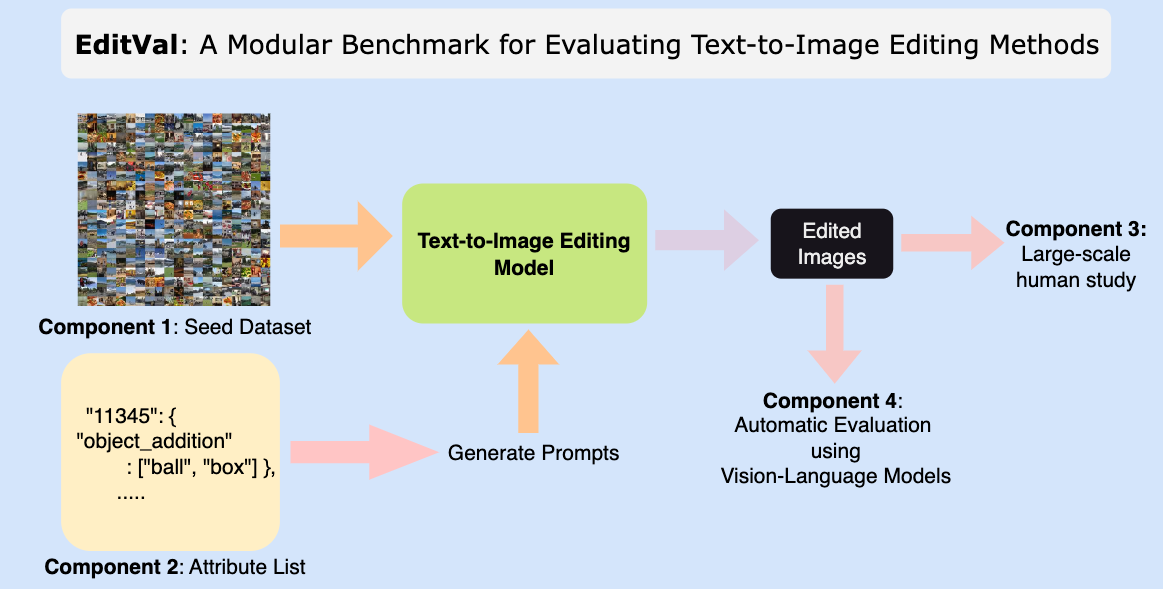
EDITVAL consists of the following distinct components:
- A seed dataset D consisting of carefully selected images from MS-COCO. These are the real images which need to be edited by the different editing methods.
- An attribute list A which consists of various dimensions in which the edits need to be made on the dataset D.
- An evaluation template and procedure for human study on the edited images.
- An automated evaluation procedure to check quality of edits using pre-trained vision-language models for a subset of attributes in A.
The attribute list A for ~100 images from MS-COCO can be downloaded from here. The format of the json file is as follows:
{
"class_name" : {
"image_id": { # image ids from MS-COCO
"edit_attribute" : {
"from" : ["initial state of attribute"],
"to" : ["target states of attribute", ...]}}}
}
The complete list of edit attributes for evaluation currently is:
- Object Addition: adding an object to the image.
- Object Replacement: replacing an existing object in the image with another object.
- Size: changing the size of an object.
- Position Replacement: changing the position of an object in the image (e.g., left, center, right).
- Positional Addition: adding an object in a specific position in the image.
- Alter Parts: modifying the details of an object.
- Background: changing the background of the image.
- Texture: changing the texture of an object (e.g., wooden table, polka dot cat).
- Color: changing the color of an object.
- Shape: changing shape of an object (e.g., circle-shaped stop sign)
- Action: changing the action that the main object is performing (e.g., dog running).
- Viewpoint: changing the viewpoint in which the image is taken from (e.g., photo of a dog from above).
More Details on EditVal Dataset and Pipeline
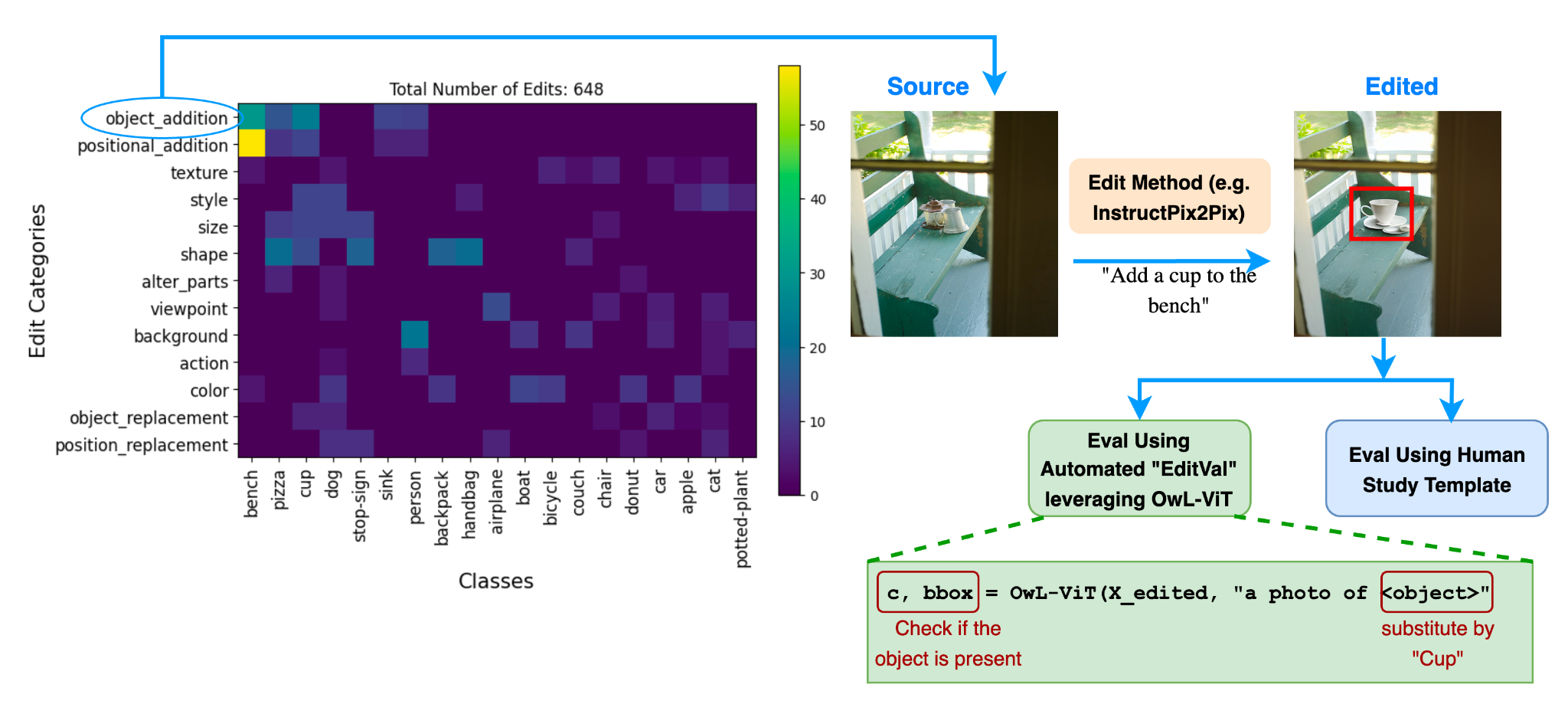
EditVal benchmark contains 648 unique image-edit operations for 19 classes selected from MS-COCO spanning a variety of real-world edits. Edit operations span simple attribute categories like adding or replacing an object to more complex ones such as changing an action, camera viewpoint or replacing the position of an existing object.
MTurk Human Study
The template to run an MTurk study to evaluate the quality of the image editting methods is provided here.
Together with the template, an input csv file must be provided for the mturk study. Each row of the csv file represents one instance of edit, which contains these four inputs:
- url_org: url of the original image.
- url_edit: url of the editted image.
- prompt: the prompt used to edit the image.
- class_name: name of the main object in the image.
An example of an input csv file can be seen here. Below is an example of how the mturk study looks to the workers.


The right image is supposed to apply the prompt "Change apple to orange" to the left image.
How well is the edit from the given prompt applied?
How well are the other properties (other than what the edit is targeting) of the main object (apple) preserved in the right image?
How well are the other properties (other than what the edit is targeting) of the main object (apple) preserved in the right image?
Leaderboards
The numbers below for the human study are calculated only on the first question of the template, which does not consider the changes to the rest of the image. This has been done in order to keep the results comparable to our automatic evaluation framework. For each instant in the human study, a score of 1.0 is given if the edit is Adequetly applied or Perfectly applied, and a score of 0.0 otherwise.
Human Study
| Method | Object Addition | Object Replacement | Position Replacement | Positional Addition | Size | Alter Parts | Average |
|---|
Automatic Evaluation
| Method | Object Addition | Object Replacement | Position Replacement | Positional Addition | Size | Alter Parts | Average |
|---|
Contact Us
Contact us at xxx@gmail.com if you wish to add your method to the leaderboards.